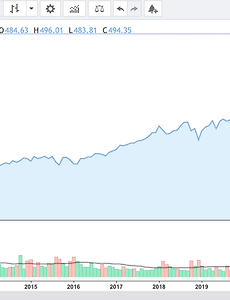
전체 글152 만약 S&P 500에 10년간 투자했더라면 어땠을까? 최근 10년간 미국 S&P 500을 추종하는 SPY는 가파르게 올랐다. 2010년 100달러에서 480달러까지 올랐으니 거의 5배나 올랐다. 역시 내가 안사면 오른다. 제 경험에 의하면 평범한 직장인들이 주식이나 코인에 대한 투자를 할 때 특정한 행동 패턴을 보입니다. 종목이 조금 오르면 팔고, 내려가면 더 내려갈까봐 팔기도 합니다. 때로는 물타기를하여 손실을 더욱 크게 만들기도 합니다. 대부분의 직장인들에게 단기적인 투자는 적합하지 않습니다. 주식 시장의 변동성과 직장 생활의 바쁜 스케줄로 인해 특정 목표를 관리하는 것이 어렵습니다. 따라서 단기 투자 보다는 장기 투자가 더욱 안정적인 선택으로 여겨집니다. 매달 꾸준히 투자하여 자신의 포트폴리오를 형성하는 것이 가장 확실한 방법입니다. 이러한 점에서 워.. 2024. 2. 3. 클린 아키텍처 - 컴포넌트 결합 - SAP 컴포넌트 결합 ADP: 의존성 비순환 원칙 (Acyclick Dependencies Principle) SDP: 안정된 의존성 원칙(Stable Dependencies Principle) SAP: 안정된 추상화 원칙(Stable Abstractions Principle) SAP 안정된 추상화 원칙(Stable Abstractions Principle) 컴포넌트는 안정된 정도만큼만 추상화되어야 한다. 고수준 정책을 어디에 위치시켜야 하는가? 시스템에는 자주 변경해서는 절대로 안 되는 소프트웨어도 있다. 고수준 아키텍처나 정책 결정과 관련된 소프트웨어가 그 예다. 업무 로직이나 아키텍처와 관련된 결정에는 변동성이 없기를 기대한다. 따라서 시스템에서 고수준 정책을 캡슐화하는 소프트웨어는 반드시 안정된 컴포넌트.. 2023. 2. 11. 클린 아키텍처 - 컴포넌트 결합 - SDP 컴포넌트 결합 ADP: 의존성 비순환 원칙 (Acyclick Dependencies Principle) SDP: 안정된 의존성 원칙(Stable Dependencies Principle) SAP: 안정된 추상화 원칙(Stable Abstractions Principle) SDP 안정된 의존성 원칙(Stable Dependencies Principle) 안정성의 방향으로(더 안정된 쪽에) 의존하라. 설계는 결코 정적일 수 없다. 설계를 유지하다 보면 변경은 불가피하다. 변경이 쉽지 않은 컴포넌트가 변경이 예상되는 컴포넌트에 의존하게 만들어서는 절대 안 된다. 변경을 쉽게 하기 위해 만든 컴포넌트에 변경이 어려운 컴포넌트가 의존하게 되면 변경을 쉽게 할 수 없게 된다. 변경이 큰 도전이 되어 버린다. 안정성.. 2023. 2. 11. 클린 아키텍처 - 설계원칙 - SRP 설계원칙 SOLID SRP: 단일 책임 원칙 Single Responsible Principle OCP: 개방-폐쇄 원칙 Open-Closed Principle LSP: 리스코프 치환 법칙 Liskov Substitution Principle ISP: 인터페이스 분리 원칙 Interface Segregation Principle DIP: 의존성 역전 원칙 Dependency Inversion Principle SRP 하나의 모듈은 하나의, 오직 하나의 이해관계자에 대해서만 책임져야 한다. 모든 모듈이 단 하나의 일만 해야 한다는 의미는 아니다. 응집된(cohesive)라는 단어가 SRP를 암시한다. 이 원칙을 위반하는 징후들을 살펴 보겠다. 징후 1: 우발적 중복 [그림 1-1 Employee 클래스] .. 2023. 2. 11. 이전 1 2 3 4 ··· 38 다음