숭실대학교 정보검색연구실 - 정보검색론(2003) 이준호 교수님 교제를 메모하기 위한 글입니다.
제 13장. 한글 색인어 추출
색인어의 단위에 따라
어절 단위 색인법
형태소 단위 색인법
n-Gram 기반 색인법으로 분류될 수 있다.
각각의 장단점에 대해서 알아 보겠다.
13.1 어절 단위 색인법
문서나 질의로부터 어절들을 인식하고, 각 어절로부터 색인어의 부분으로서 무의미한 비색인 분절을 제거한 나머지 색인 분절을 색인어 후보로 선정한 후, 이들로부터 불용어를 제거하는 방법이다.
한글에서 문서나 질의를 표현할 수 있는 체언이나 용언의 명사형 뒤에 조사나 접미사 등이 붙는다는 특성에 근거하여 어절로부터 조사나 접미사 등을 제거하는데 중점을 둔다.
비색인 분적이란 체언의 뒤에 붙여 쓰이지만 색인어에 포함시키기에는 무의미한 조사, 어미, 접미사 등의 음절들을 말한다.
|
|
- 비색인 분절 -
어절 단위 색인법의 색인 과정은 대체로 3단계로 구성된다.
1 단계 : 빈칸과 같은 문자를 구분자로 하여 문서에서 어절들을 인식한다.
2 단계 : 인식된 각 어절에 대해 비색인 불절을 제거한다. 일반적으로 최장 일치법(maximum matching method)이 이용된다.
최장 일치법이란 주어진 어절 내에서 검출될 수 있는 비색인 분절들 중에서 가장 긴 분절을 선택하는 방법이다. 예) "시스템으로부터" => "으로부터", "로부터", "부터"의 비색인 분절 중에서 가장 긴 "으로부터"가 불용어처리 된다.
3 단계 : 불용어를 제외한 나머지 색인 분적들을 색인어로 선정한다.
최장 일치법을 사용하여 비색인 분절을 제거하면 구현이 간단하지만 오류로 인하여 추출되는 색인어의 일관성이 떨어질 수 있다.
예) "벨기에로서는"과 "벨기에"의 두 어절에 대해 "에로서는"이 어절 단위 색인법이 제거시켜 "벨기"가 색인되어 "벨기에"와 다른 색인어가 된다.
한글은 조사, 어미, 접미사 등과 같은 단순 비색인 분절을 2,000개 이상 포함하고 있다.
한글은 복합 명사를 구성하는 단순 명사들 사이의 띄어 쓰기를 자유롭게 규정하고 있다.
문서들이 복합 명사를 많이 포함하고 있을 경우, 어절 단위 색인법은 검색 효과를 저하시키는 문제점이 있다.
예) "정보검색"과 "정보 검색". 어절 단위 색인법의 1단계인 띄어쓰기 단위로 어절을 분리하면서 다른 단어로 색인된다.
13.2 형태소 단위 색인법
문장 분석의 정도에 따라 형태소 해석만을 이용하는 방법
구문 해석을 이용하는 방법으로 구분된다.
|
형태소 해석 |
구문 해석 |
색인과정 |
1. 어절들에 대한 형태소 해석 2. 형태소 해석의 애매성 제거 3. 명사 추출 4. 불용어 제거 |
1. 어절들에 대한 형태소 해석 2. 형태소 해석의 애매성 제거 3. 형태소 해석 결과를 이용한 구문 분석 4. 명사 추출 5. 불용어 제거 |
<표 13.1> 형태소 단위 색인법
형태소 해석만을 이용하는 방법
문장의 모든 어절들에 대해 형태소 해석을 수행하여, 최소 의미의 명사들을 문서와 질의의 표현을 위한 색인어로 선정한다.
이 방법은 형태소 해석, 애매성 제거, 단순 명사 추출, 불용어 제거의 4 단계를 거처 색인을 수행한다.
형태소 해석 : 문장을 최소의 의미 단위로 구분하여 문장 내의 각 어절을 구성하고 있는 형태소를 파악
애매성 제거 : 단어나 어절 자체의 모호함 때문에 하나의 단어나 어절에 대해 여러 개의 해석 결과가 산출되는 형태소 해석의 애매함을 제거. 즉, 여러 개의 형태소 해석 결과로 부터 하나만 선정
선택된 해석 결과로부터 단순 명사와 같은 최소 의미의 형태소들을 추출
불용어를 제외한 나머지를 색인어로 선정
구문 해석을 통한 형태소 해석에서 한 단계 더 나아가 문장 단위의 구문 해석을 수행하여 문장에서 중요한 의미를 갖는 특정한 명사나 명사구를 색인어로 선정한다.
어절 단위 색인법과 형태소 단위 색인법은 최종적으로 추출되는 색인어의 단위에서 구별된다.
어절 단위 색인법 : 여러 개의 명사가 결합된 복합 명사를 포함한 어절의 경우에도 단순히 조사나 접미사 등의 절단만을 수행하고 나머지 분절을 색인어로 취한다.
예) "정보검색서비스가" ==> "정보검색서비스"
형태소 단위 색인법 : 복합 명사 어절을 최소 의미의 형태소로 분리하여 단순 명사를 색인어로 선정 할 수 있다.
예) "정보검색서비스가" ==> "정보", "검색", "서비스"
복합 명사의 띄어 쓰기 문제는 형태소 단위 색인법을 사용하여 단순 명사들을 색인어로 추출함으로써 극복될 수 있다.
형태소 단위 색인법은 한계:
형태소 해석이나 구문해석과 관련하여 다음과 같은 몇 가지의 문제점을 지니고 있다.
첫째, 형태소 단위 색인법은 형태소 해석이나 구문 해석 과정에서 형태소 사전, 격틀 사전 등의 언어 정보들을 필요로한다. 특히 형태소 사전은 많은 개발 시간과 비용을 요구하며, 형태소 해석의 대상이 되는 문서들의 성질에 크게 의존하는 경향이 있어 문서의 종류마다 서로 다르게 개발되어야 하는 부담을 안고 있다.
둘째, 형태소 단위 색인법은 형태소 해석에 의존하므로 형태소 해석 과정에서의 오류는 부정확한 색인어들의 생성을 야기한다. 형태소 해석의 가장 큰 오류는 사전 내에 등록되지 않은 미등록어로 인해 발생하며, 특히 과학 기술 분야에서는 많은 전문 용어들이 미등록어로 처리되어 검색 효과가 감소 될 수 있다. 그 외에도 단어나 어절 자체의 모호함에서 오는 형태소 해석의 애매성이나, 실제 문서에서 많이 발견되는 철자 오류와 띄어 쓰기 오류 등의 비문법적인 어절들도 형태소 해석 오류의 원인이 되어 있다.
셋째, 형태소 단위 색인법은 형태소 해석이나 구문 해석 과정에서 복잡한 규칙을 요구한다. 예를 들어, 문장 구성 성분들의 순서가 도치되거나 구성 성분의 역할을 결정하는 조사나 어미 등의 생략은 구문 해석을 어렵게 한다.
원인 |
입력 어절 |
잘못된 형태소 해석 결과 |
애매한 형태소 해석 |
10 년 형을 선고함 |
선/보통명사+고함/보통명사 선고/보통명사+함/보통명사 |
미등록어 |
가내공장으로 |
가/보통명사+내/보통명사+공장/보통명사+으로/부사격조사 |
비문법적 어절 띄어쓰기 오류 |
추출하였다고하자 공유할수있는 |
추출하였다고/동작성보통명사+하/파생접미사+자/연결어미 공유할수있/보통명사+는/주격조사 |
13.3 n-Gram 기반 색인법
2-Gram 기반 색인법의 예
'정보검색론' 카테고리의 다른 글
| 제 17장. 질의 확장 (0) | 2018.05.10 |
|---|---|
| 정보검색론 16장. 확률 모델 (0) | 2018.05.10 |
| 정보검색론 제 15장. 확장 불리안 모델 (0) | 2018.05.03 |
| 정보검색론 제 12장. 유사도 계산 (0) | 2018.04.18 |
| 정보검색론 제 11장. 정합성 피드백 (0) | 2018.04.18 |
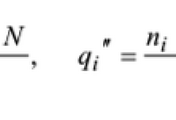

댓글